And one more article is blooming now. For a time I've been thinking about this specific article: how to do some [basic] stuff in Excel. (I call it 'basic' because you probably will use it very constantly.) Stuff that is actually helpful, and simple to do -- not like the previous article that was a bit more complex than first intended -- but actually so simple that you need not be an Excel expert to do it.
First of all, why I should be talking about Excel? I'm specialized in software engeneering, so maybe I should keeping talking about scripting or maybe even programming. But the truth is that Excel is the most useful tool in my computer, way above any IDE that I have here or scripting tool or whatever.
Why? Excel is capable of scripting, for one thing. Second, there's no more intuitive way of organizing data for a human beam than using a bidime
nsional table. Finally, Excel can help us format this data in a very professional (which means "pretty") way, automatically.
I. Removing Duplicates
That said, one of the bests uses for excel is to gath
er data... maybe records from a report, maybe names from a list, whatever. This data often contains duplicates that need to be removed so that the analisys can be made. There are many different ways to remove those duplicates -- and in Excel 2007 Microsoft has finally included a functionality that does this for us.
But since most of us still use Excel 2003 or less, it's very important to know how to best do this. So, here's a very simple tutorial:
1. Define the Key Column
The first step is to define which column(s) will be used in the duplicated comparison. Let's ilustrate: you have a employee list. On column A is the employee name, on B his last name, on C his carrer level name and on D his montly wage. You know for a fact that someone screwed up the report and there are duplicates records -- the same employee appears more than once on the list. It's your purpose to create SERIAL NUMBER
S for your employees, but first you will need to clean-up the list.
However, you also expect to have duplicates first names in your organization, after all, we are talking about a lot of people. So to determine that th
e record is a duplicate of a previous one? You will have to join the Last Name and the First Name to create a third column. This column will be called your KEY column, and it's where we check for duplicates.
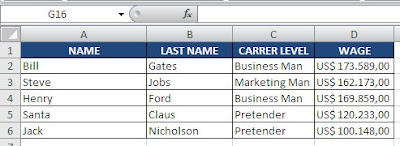
Example Sheet
In our example, the "KEY" column is the concatenation of both NAME and SERIAL NUMBER. We create this in the E column. To concatenate both values, you can either use the CONCATENATE function or just the join operator (&); I preffer the latter, so your cells should have the following formula:
=B2&A2
...which is self-explanatory. This column should not have duplicates -- and this is how you ensure that:
- Sort your KEY column (E) in Ascending Order.
- Create another column, labelled DUPLICATED?, which should compare if a given item from column E is equal to the previous one, using the formula:
=E2=E1
Resulting in true for whatever lines are duplicates from the first one. - No you can filter you sheet to select only duplicated lines:

Before filtering...

...and after filtering.
- Now, all you have to do is exclude the duplicated lines. To do this, select the first line (in the example, click on "Henry"), then, holding both CTRL and SHIFT, press "down" once, which should select all cells in A. Now, hold SHIFT only and press "space". This will select the whole line (even empty cells). Right-click the selecion and choose "Delete Row".
- Clear the filter and the duplicated will have disappeared.
That's all for this tip. It's quite easy to do this when after you did it two or three times, and it's handy. Users of Excel 2007 might even preffer to remove duplicates this way since you will see exactly what you are removing.
Next week I will post another tip, this time on coloring odd lines in a document.


